

NVIDIA Set Up
What Happens When $90 Billion of GPUs Every 90 Days Becomes the Baseline?


NVDA Earnings Preview: Is $1 billion Installed per Day even Logistically Possible? Robots?
The debate into NVDA earnings is no longer whether demand is strong.
Of course, demand is strong.
The real debate is whether the expectations embedded in the stock — and, more importantly, in consensus numbers — have quietly become almost impossible to satisfy for very long. It’s Saturday and I am sitting here wondering what would be “enough” to satisfy the markets on 5/20 (Wednesday) from Jensen and Co?
Look at the Data Center revenue ramp:

That is THE most violent revenue ramps ever seen in large-cap history. EVER!
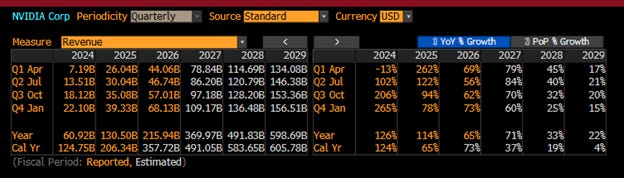
But here is the key point: the stock is no longer priced simply for extraordinary growth. It is priced for the continuation of extraordinary sequential acceleration. And remember with 24.2 billion shares out, each $1 billion of revenue upside equates to about 2.5 cents per share!
The Street effectively needs NVDA to keep adding something like $10B of incremental revenue every quarter just to maintain the current framework. Think about how insane that actually is. At $20B or $30B of quarterly revenue, maybe you can underwrite that kind of growth. At a nearly $80B quarterly total-company run-rate, every incremental quarter becomes a logistical, electrical, financial, and physical feat.
That is the setup.
The company may beat again. Jensen may guide higher again. Collette will do her usual word salad and Jensen will answer questions with a filibuster so you do not ever get the full answer. Demand may still be ahead of supply. But the bar has moved from “is AI demand real?” to “can NVDA keep compounding at a scale that is becoming almost impossible to visualize?”
The Demand Side Is Also Getting Insane
To be fair, the counterargument is powerful. The reason compute still feels scarce may be that usage is actually exploding faster than even the bulls expected. Look at the AI labs. Anthropic’s run-rate revenue has gone vertical. Recent reports peg Anthropic at more than $30B of annualized revenue run-rate early April and now some talk of $45 billion in May, up from roughly $9B at the end of 2025. OpenAI is a bit more opaque but Sam Altman has thrown out crazy stats on Codex usage such as boasting over 4 million weekly active users, experiencing a massive surge that added 1 million users in less than two weeks. OpenAI sizing in ARR was reported to top $25B of annualized revenue as of the end of February 2026, up from $21.4B at the end of 2025 and market talk is well north of $30 billion as we speak. Those are ridiculous numbers. The entire SaaS market for CRM and related took 25 years to get to this size.
And they matter for NVDA because this is the part of the debate that the bears can underappreciate. Token usage is not growing linearly. It is going vertical. Companies are building internal token leaderboards. Developers are token-maxxing. API calls are exploding. Coding agents, research agents, customer support copilots, finance tools, legal tools, sales tools — everything is becoming an API draw on a frontier model or a private model.
This is the best explanation for why the industry can be drowning in GPU supply and still feel compute constrained.
The old framework was: “How many users are using ChatGPT?”
The new framework is: “How many tokens are being consumed per workflow, per employee, per day, across every enterprise process?”
I had dinner with a friend who works at the largest consulting firm, and the way he described enterprise AI adoption really stuck with me. He said companies are not using AI purely as a replacement yet. In some cases they are, but for the most part, they are running AI in parallel with existing systems. They know AI is 80% there, not 100% there. So they do not rip out the old workflow on day one. They run both.
That is important.
Because parallel systems are actually more compute intensive in the short term, not less. You are not immediately deleting the old process. You are adding an AI layer on top of it. Then, piece by piece, as confidence improves, AI starts taking share from the legacy workflow.
His point was simple: literally every company is doing this.
That is the bull case in human terms. This is not just labs training bigger models. It is every enterprise gradually inserting AI into every workflow, even before they fully trust it. And if every company is running parallel AI systems while token usage per workflow is rising, then maybe the compute appetite is even more absurd than the revenue ramp suggests.
That is why the setup is so hard.
